AIDA64
AIDA64 Extreme Edition is a streamlined Windows diagnostic and benchmarking software for home users. AIDA64 Extreme Edition provides a wide range of features to assist in overclocking, hadware error diagnosis, stress testing, and sensor monitoring. It has unique capabilities to assess the performance of the processor, system memory, and disk drives. AIDA64 is compatible with all current 32-bit and 64-bit Microsoft Windows operating systems, including Windows 7 and Windows Server 2008 R2.
Memory Read
[HR][/HR]This benchmark measures the maximum achiveable memory read bandwidth. The code behind this benchmark method is written in Assembly and it is extremely optimized for every popular AMD and Intel processor core variants by utilizing the appropriate x86, MMX, 3DNow!, SSE, SSE2 or SSE4.1 instruction set extension. The benchmark reads a 16 MB sized, 1 MB aligned data buffer from system memory into the CPU. Memory is read in forward direction, continuously without breaks.
In order to avoid concurrent threads competing over system memory bandwidth, Memory Read benchmark utilizes only one processor core and one thread.
Memory Write
[HR][/HR]This benchmark measures the maximum achiveable memory write bandwidth. The code behind this benchmark method is written in Assembly and it is extremely optimized for every popular AMD and Intel processor core variants by utilizing the appropriate x86, MMX, 3DNow!, SSE or SSE2 instruction set extension. The benchmark writes a 16 MB sized, 1 MB aligned data buffer from the CPU into the system memory. Memory is written in forward direction, continuously without breaks.
In order to avoid concurrent threads competing over system memory bandwidth, Memory Write benchmark utilizes only one processor core and one thread.
Memory Copy
[HR][/HR]This benchmark measures the maximum achiveable memory copy speed. The code behind this benchmark method is written in Assembly and it is extremely optimized for every popular AMD and Intel processor core variants by utilizing the appropriate x86, MMX, 3DNow!, SSE, SSE2 or SSE4.1 instruction set extension. The benchmark copies a 8 MB sized, 1 MB aligned data buffer into another 8 MB sized, 1 MB aligned data buffer through the CPU. Memory is copied in forward direction, continuously without breaks.
In order to avoid concurrent threads competing over system memory bandwidth, Memory Copy benchmark utilizes only one processor core and one thread.
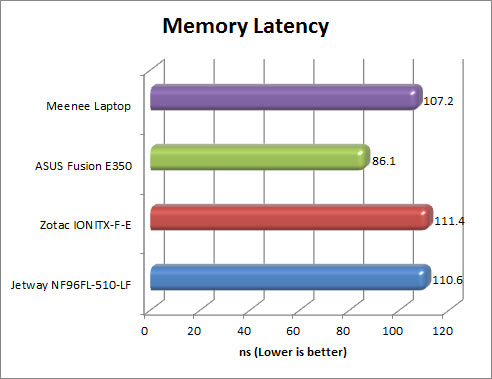
Memory Latency
[HR][/HR]This benchmark measures the typical delay when the CPU reads data from system memory. Memory latency time means the penalty measured from the issuing of the read command until the data arrives to the integer registers of the CPU. The code behind this benchmark method is written in Assembly, and uses 1 MB alignment, 1024-byte stride size. Memory is accessed in forward direction.
Memory Latency benchmark test uses only the basic x86 instructions and utilizes only one processor core and one thread.
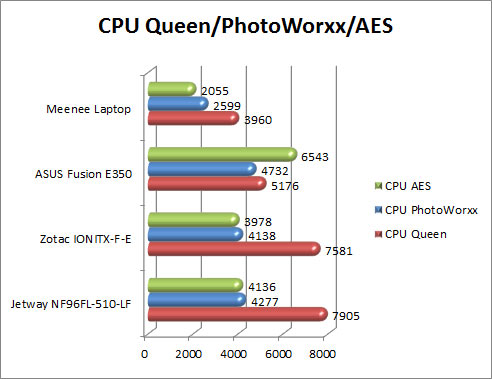
CPU Queen
[HR][/HR]This simple integer benchmark focuses on the branch prediction capabilities and the misprediction penalties of the CPU. It finds the solutions for the classic “Queens problem” on a 10 by 10 sized chessboard (http://mathworld.wolfram.com/QueensProblem.html).
At the same clock speed theoretically the processor with the shorter pipeline and smaller misprediction penalties will attain higher benchmark scores. For example — with HyperThreading disabled — the Intel Northwood core processors get higher scores than the Intel Prescott core based ones due to the 20-step vs 31-step long pipeline. However, with enabled HyperThreading the picture is controversial, because due to architectural bottlenecks the Northwood core runs out of internal resources and slows down. Similarly, at the same clock speed AMD K8 class processors will be faster than AMD K7 ones due to the improved branch prediction capabilities of the K8 architecture.
CPU Queen test uses integer MMX, SSE2 and SSSE3 optimizations. It consumes less than 1 MB system memory and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
CPU PhotoWorxx
[HR][/HR]This integer benchmark performs different common tasks used during digital photo processing.
It performs the following tasks on a very large RGB image:
This benchmark stresses the integer arithmetic and multiplication execution units of the CPU and also the memory subsystem. Due to the fact that this test performs high memory read/write traffic, it cannot effectively scale in situations where more than 2 processing threads used. For example, on a 8-way Pentium III Xeon system the 8 processing threads will be “fighting” over the memory, creating a serious bottleneck that would lead to as low scores as a 2-way or 4-way similar processor based system could achieve.
CPU PhotoWorxx test uses only the basic x86 instructions, and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
CPU AES
[HR][/HR]This integer benchmark measures CPU performance using AES (a.k.a. Rijndael) data encryption. It utilizes Vincent Rijmen, Antoon Bosselaers and Paulo Barreto’s public domain C code in ECB mode.
CPU AES test uses only the basic x86 instructions, and it’s hardware accelerated on VIA PadLock Security Engine capable VIA C3, VIA C7 and VIA Nano processors; and on Intel AES-NI instruction set extension capable processors. The test consumes 48 MB memory, and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
CPU ZLib
[HR][/HR]This integer benchmark measures combined CPU and memory subsystem performance through the public ZLib compression library Version 1.2.5 (http://www.zlib.net).
CPU ZLib test uses only the basic x86 instructions, and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
CPU Hash
[HR][/HR]This integer benchmark measures CPU performance using the SHA1 hashing algorithm defined in the Federal Information Processing Standards Publication 180-3 (http://csrc.nist.gov/publications/fips/fips180-3/fips180-3_final.pdf). The code behind this benchmark method is written in Assembly, and it is optimized for every popular AMD, Intel and VIA processor core variants by utilizing the appropriate MMX, MMX+/SSE, SSE2, SSSE3, or AVX instruction set extension. This benchmark is hardware accelerated on VIA PadLock Security Engine capable VIA C7 and VIA Nano processors.
In this benchmark every thread is working on independent 8 KB data blocks, and the MMX, SSE2 and SSSE3 optimized calculation routines implement the latest vectorization idea of Intel (http://software.intel.com/en-us/articles/improving-the-performance-of-the-secure-hash-algorithm-1/).
FPU VP8
[HR][/HR]This benchmark measures video compression performance using the Google VP8 (WebM) video codec Version 0.9.5 (http://www.webmproject.org). FPU VP8 test encodes 1280×720 pixel (“HD ready”) resolution video frames in 1-pass mode at 8192 kbps bitrate with best quality settings. The content of the frames are generated by the FPU Julia fractal module. The code behind this benchmark method utilizes the appropriate MMX, SSE2 or SSSE3 instruction set extension, and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
FPU Julia
[HR][/HR]This benchmark measures the single precision (also known as 32-bit) floating-point performance through the computation of several frames of the popular “Julia” fractal. The code behind this benchmark method is written in Assembly, and it is extremely optimized for every popular AMD, Intel and VIA processor core variants by utilizing the appropriate x87, 3DNow!, 3DNow!+, SSE, or AVX instruction set extension.
FPU Julia test consumes 4 MB system memory per calculation thread, and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
FPU Mandel
[HR][/HR]This benchmark measures the double precision (also known as 64-bit) floating-point performance through the computation of several frames of the popular “Mandelbrot” fractal. The code behind this benchmark method is written in Assembly, and it is extremely optimized for every popular AMD, Intel and VIA processor core variants by utilizing the appropriate x87, SSE2 or AVX instruction set extension.
FPU Mandel test consumes 4 MB system memory per calculation thread, and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
FPU SinJulia
[HR][/HR]This benchmark measures the extended precision (also known as 80-bit) floating-point performance through the computation of a single frame of a modified “Julia” fractal. The code behind this benchmark method is written in Assembly, and it is extremely optimized for every popular AMD, Intel and VIA processor core variants by utilizing trigonometric and exponential x87 instructions.
FPU SinJulia test consumes 256 KB system memory per calculation thread, and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
Philips is well known for its monitors, but its Evnia series stands as the jewel…
Alongside AMD servers, MSI showcased its NVIDIA MGX AI servers and Intel Xeon 6 solutions…
Intel has its Gaudi 2 accelerators available, and Gaudi 3 will be available soon. But…
Intel has just dropped a brand new update for its Arc GPU graphics drivers, but…
The latest keyboard from Epomaker is here, with the Galaxy 100, a $110 fully customisable…
Corsair has just announced the LX-R RGB Series, a new line of reverse-flow cooling fans…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}