Leaked AMD RX 480 Launch Slides Reveal All
Samuel Wan / 8 years ago
With just hours to go until the RX 480 finally launches, somehow, many of the launch slides have ended up on the internet. Usually, we would have these slides leaked much earlier and the lack of such leaks have suggested that AMD has been running a tighter and tighter ship these days. While you’re sure to see the full set later today, we’ve decided to share a few highlights from the already leaked slides.
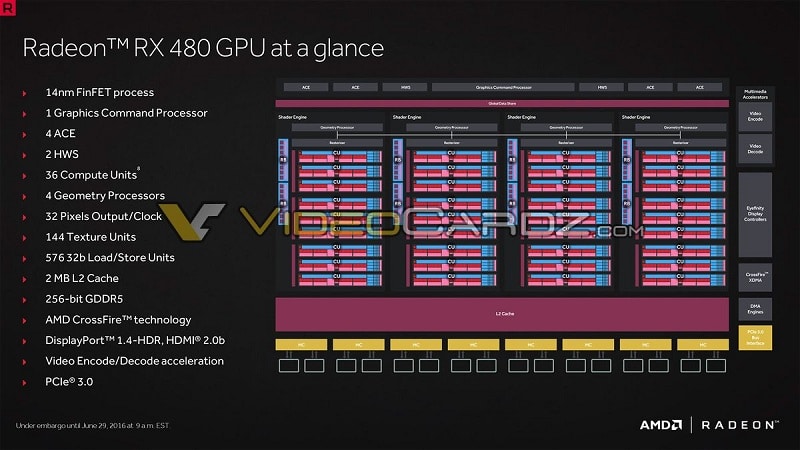
First off, Polaris and the RX 480 utilize a new version of AMD’s current architecture GCN 4.0. This brings a number of major improvements and new hardware additions. The slides also confrim that the GPU will have 36 CUs for 2304 shaders and 144 TMUs.
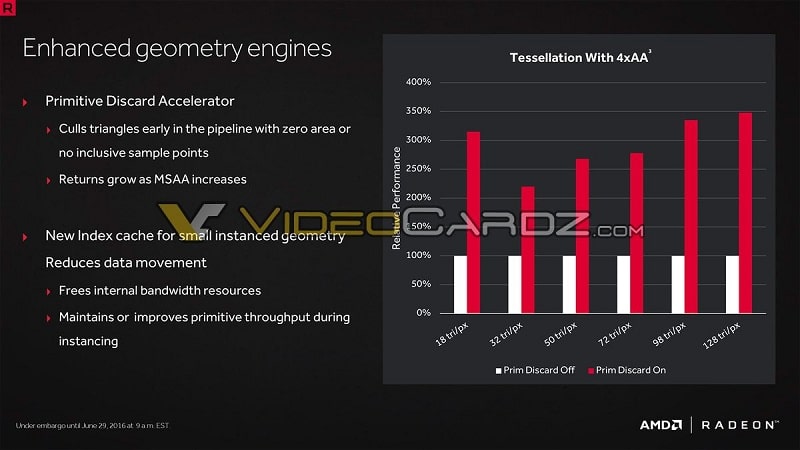
One improvement is the Primitive Discard Accelerator. This culls and discards triangles invisible to the user at an early stage of the pipeline. For instance, a game may tell the GPU to render a tree and a house. The full house and free are then processed. However, the tree might block part of the house, meaning work done on that part of the house is wasted. The PDA will now prevent this waste.
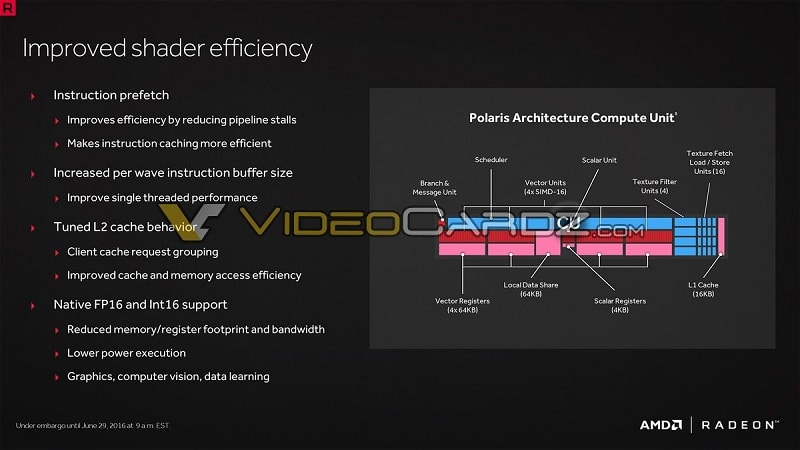
Next, AMD has tuned efficiency by increasing the L2 cache and instruction buffer sizes. In addition to improved pre-fetch, this means shaders will spend more time working than waiting. F16 and Int16 support have been added natively as well, allowing for hlaf=precision workloads to complete more efficiently.
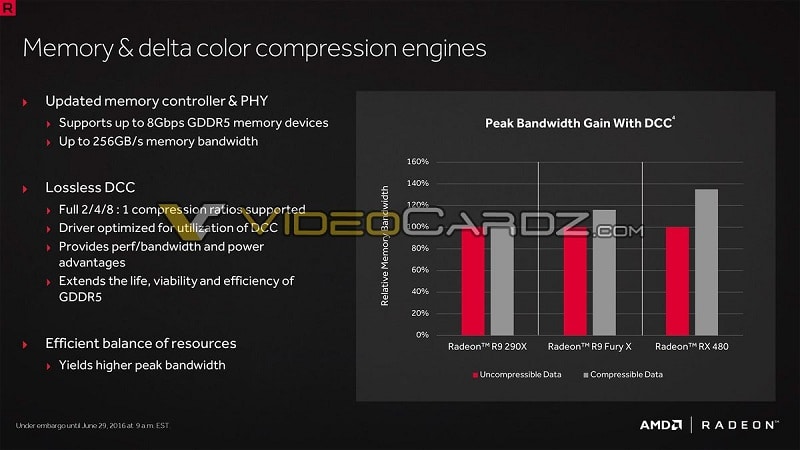
Another major change is the improved delta color compression to improve effective memory bandwidth. This was first introduced with GCN 1.2/3.0 and has been vastly improved. While GCN 1.2 couldn’t quite surpass larger bus width GCN 1.0/1.1 GPUs, the RX 480 won’t have any problems matching the bandwidth available to the R9 390 and 390X.
Lastly, we have the addition of HWS hardware schedulers for asynchronous compute. This adds onto the Asynchronous Compute Engines already in place with even more offloading from the CPU, extra asynchronous tasks available and load balancing. This should provide an even larger leg up for AMD compared to Pascal which was only a minor improvement over Maxwell in terms of async compute, especially as the architecture continue to age.

With the teaser showcasing all of these improvements, all we’re waiting for is some real world performance numbers. Luckily, we’ve got that covered with our review later today. Don’t worry because we’ve got that covered for later today!


















